
This week is International Archives Week. Around the globe archivists are celebrating how they Empower Knowledge Societies! In keeping with the celebration, I’d like to first share what we do, who we serve, and how. Then I'll introduce our audiences to a new information management system implemented by the Institute Archives, called ArchivesSpace and explain how we came to this implementation. Finally, I'll touch on why this is so important.
We (the archivists) operate according to our mission. We are required to select, appraise, organize, manage, and maintain Institute records of historical value and special collections materials. We have to make practical sense (and provide historical context) before the researcher can get adequate access to records and manuscripts. We are also required to provide facilities for the retention, preservation, servicing, and research use of our materials, and serve as a research center for the study of the Institute’s history and the history of science and technology. We also serve the Institute’s administration and operations by promoting knowledge and understanding of their development. This mission now extends to the digital environment in addition to the analog materials that we continue to collect and manage.
Traditionally, if anyone wanted to conduct research with our archival records, they were required to set up a special visit to Rensselaer and pore over documents to gather the data they were looking for. For example, remember the book The Great Bridge, by David McCullough? The author spent months with the Roebling collection when it was housed in a small room located in the old library (now the Voorhees Computing Center) during the 1960s in order to write his famous book about the Brooklyn Bridge. This was long before collections began to be accessible to the world via the Web.
Starting in the late 1990s, as the internet was starting to take off, archives, museums, and libraries began digitizing all sorts of collections to showcase what they have in their repositories and began sharing them on the World Wide Web, making their archival material visible and accessible in unprecedented ways. All kinds of databases started to develop that catered to these needs. In the early 2000s the Institute Archives implemented a couple of databases for just this reason, and for almost two decades we've shared historical photographs, the student newspaper, and documents from the manuscript collections. None of these databases could be connected easily though. They’ve been proprietary systems (owned and controlled by a vendor) - what we call information silos. We could never really point the researcher to a digitized document and then provide the appropriate context for where the physical document lives within a particular collection.
In the spring of 2011, I implemented the archives first archival description system (called Archon) so that lists and inventories of our records and manuscript holdings could be discovered and searchable more easily online. This connected a global community of researchers to collections like George Low’s NASA papers, or Eben Horsford’s baking powder records. This was an open source database created by a couple of archivists from the University of Illinois-Urbana-Champaign. It was a fantastic system and revolutionized the way we provided knowledge of and access to the records we house. Sadly, Archon became unstable and the technology it was built with became outdated. In order to sustain an open source system, money and an extremely large community of users is required to sustain it. Last fall, with the impending doom of Archon inching closer, we secured a new open source system called ArchivesSpace which is supported by an incredibly large pool of colleges and universities (Yale, MIT, NYU – to name a few).
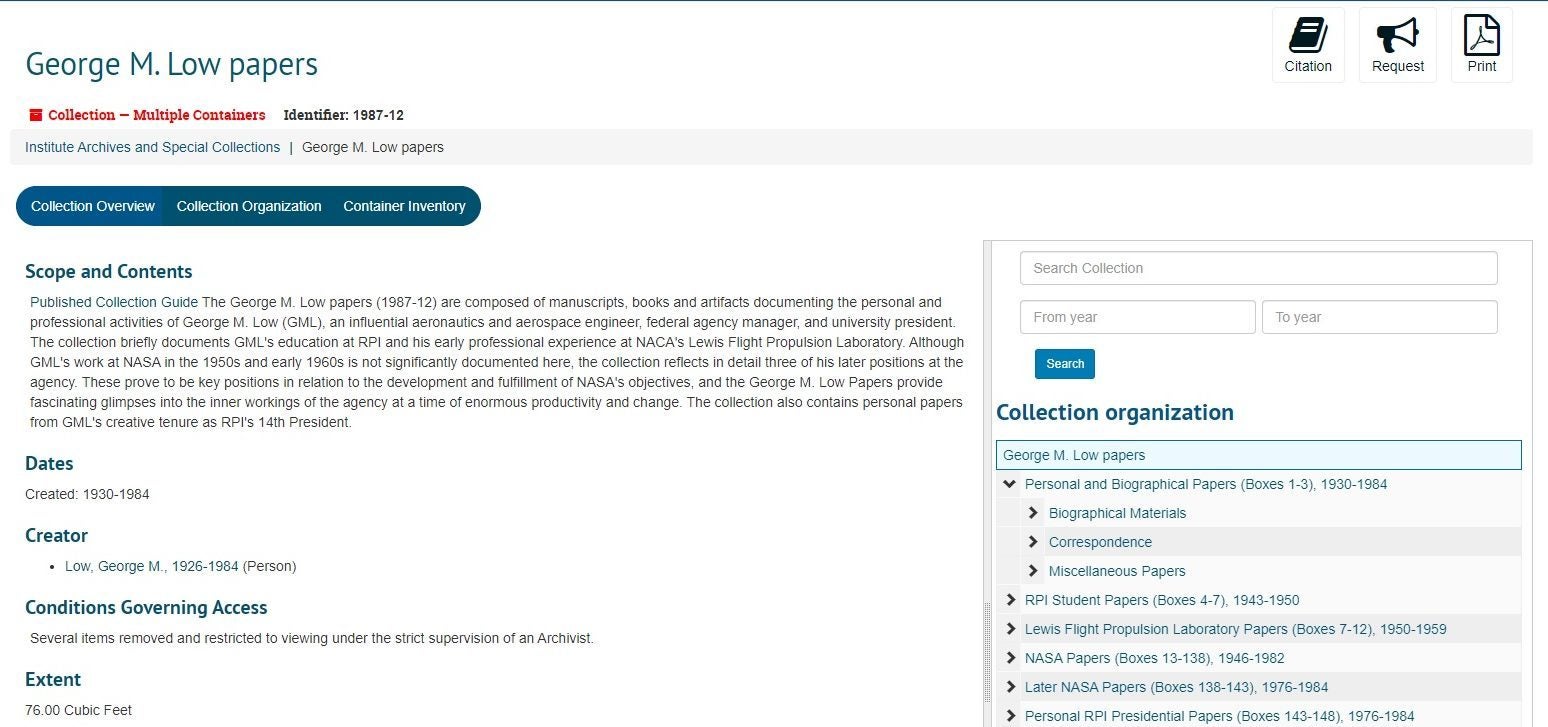
This past spring we (the Institute Archives and Special Collections) rolled out ArchivesSpace for managing and providing web access to descriptive information and inventories of records and various collections we house in the Institute Archives. This revolutionizes our management practices and will, down the road, dynamically impact additional systems we are working on replacing to better serve our communities!
Times have changed, the web has changed, technology and information exchange has also changed. These changes have driven not just how we work, but also how we assist the research endeavors of our communities. In 2016 we began investigating new open source platforms for better access and connectivity to the Institute Archives digital collections, including the inventories I spoke of earlier. This is very labor intensive work that takes time and expertise! I only wish we could easily pull out the data and associated digital collections from one database and move everything into another but unfortunately it doesn't work that way. We have pored over thousands of bits of data (and continue to do so), we've had to figure out new workflows and collection management tactics and strategies, training ourselves and others how to move from one system to another, and then make it pretty(!) for the "end-user." Why do we do this? For starters, we’re required to collect, protect and preserve nearly two hundred years of the Institute's history, so we're immersed in both analog and the digital worlds now. But moreover the data landscape in the 21st century and expectations of information seekers is always changing therefore we're always striving to ensure we deliver benefits to citizens and Knowledge Societies.
Next, you’ll hear from Tammy who will regale you of another system implementation we’ve been working on!
